Experiments with Latent Dirichlet Allocation
In a couple of my previous posts I talked about using clustering colors with k-means and counting clusters with EM. This kind of clustering is fairly straightforward, as you have some notion of distance between points to judge similarity. But what if you wanted to cluster text? How do you judge similarity there? (There are certain measures you could use, like the F-measure, which I'll talk about in a later post.)
One way is to use Latent Dirichlet Allocation, which I first heard about while talking to a Statistics 133 GSI, and then later learned about while reading probabilistic models of cognition. Latent Dirichlet Allocation is a generative model that describes how text documents could be generated probabilistically from a mixture of topics, where each topic has a distribution over words. For each word in a document, a topic is sampled, from which a word is then sampled. This model gives us probabilities of documents, given topic distribution and words. But what's more interesting here is learning about topics given the observed documents.
Here's the plate notation view of LDA, which describes exactly how documents are generated:

The image above was created using TiKZ-bayesnet (TiKZ is super-fun by the way) for LaTeX, which actually provides an LDA example. I've taken their example here and modified the variable names and layout slightly to match my code.
Each box is a "plate" which signifies that the structure should be repeated according to the sequence in the plate's lower right corner. Think of it like a "for-loop" for graphs.
- Now I'll go over all these variables.
$alpha_{topics}$ and $alpha_{words}$ are hyperparameters that you set by hand. They show how the Dirichlet distributions create distributions over topics and words, respectively. A Dirichlet distribution outputs a vector that sums to 1, which can be used as the probabilities for a multinomial distribution. We'll usually set $alpha_{topics}$ and $alpha_{words}$ to be a number greater than 0, but much less than 1. The idea here is that we generate mixtures that are very different from each other. Take a look at the picture below, which represents some sampling from a Dirichlet distribution over 3 categories for different values of the $alpha$ parameter. (Actually $alpha$ is itself a vector of 3 numbers, so $alpha$ of 1 really means $alpha$ is [1, 1, 1])
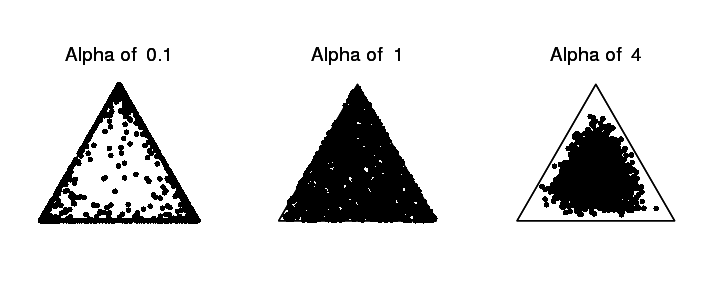
The leftmost distribution creates highly varied samples. Think of the three points as the proportion of three different words, like "dog", "cat", and "mouse", and we're generating topics. This might create topics like [8, 0.1, 0.1] (mostly dog), [0.2, 0.9, 0] (mostly cat), etc. Whereas the rightmost distribution creates topics that are much more in the center, which means they're much closer to each other. Here we might create topics like [0.3, 0.4, 0.3], which means the word "dog", "cat", and "mouse" are almost equally likely to be generated by this topic. Smaller alpha values ...







{kind=link}