 Josh Moller-Mara
Josh Moller-Mara
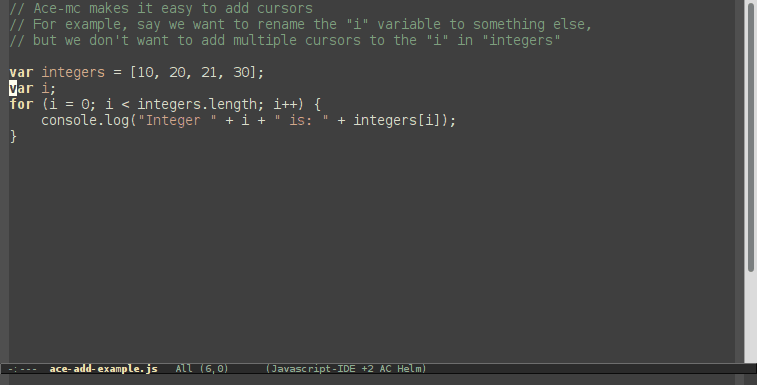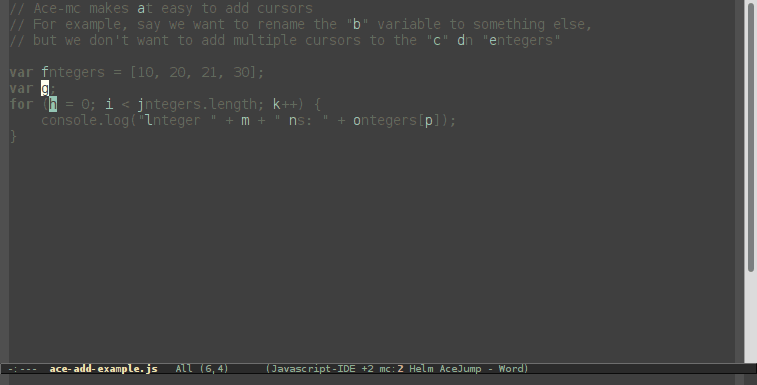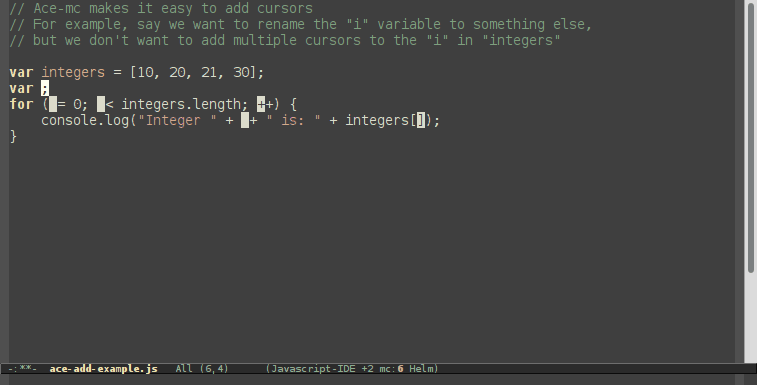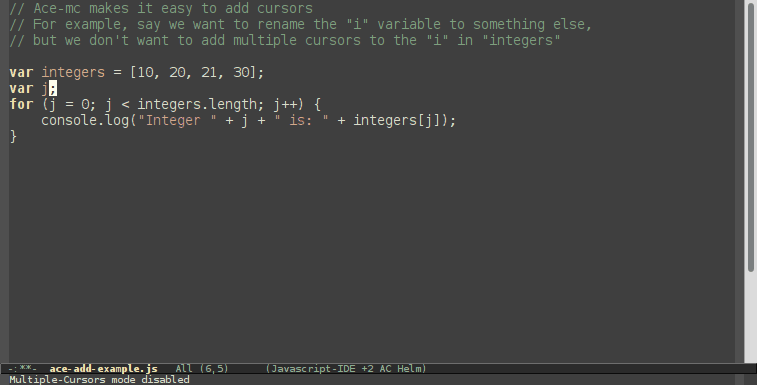
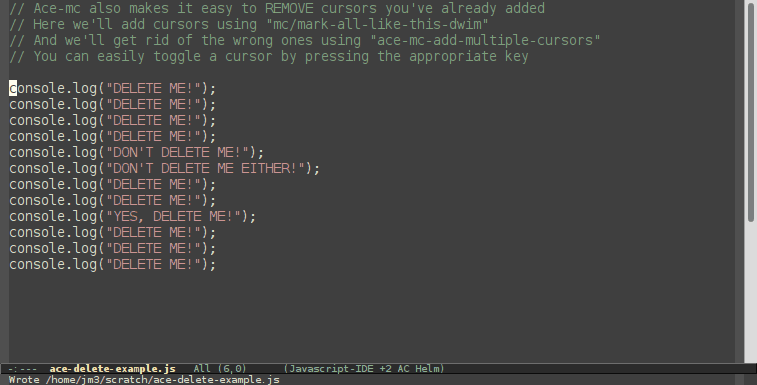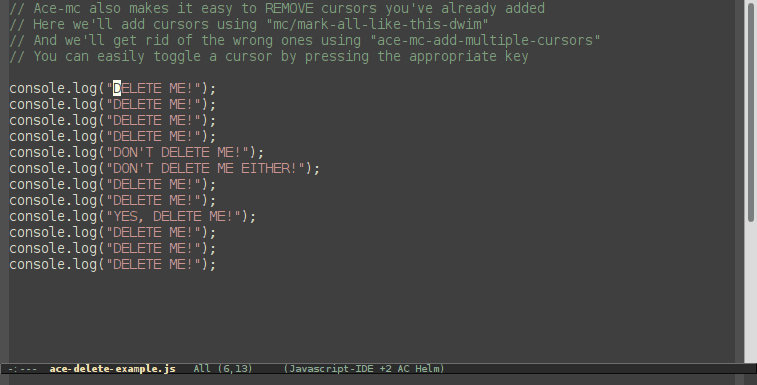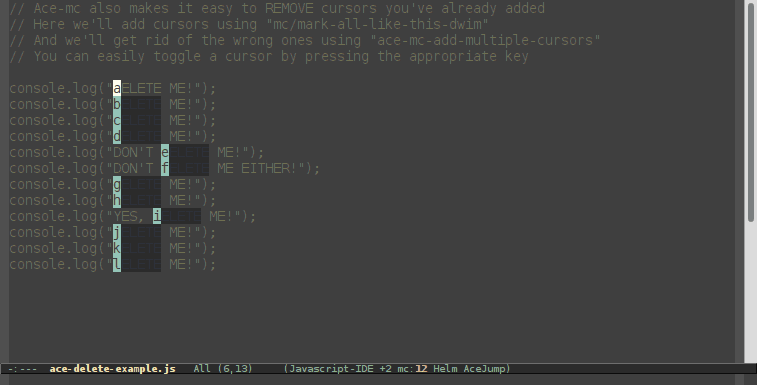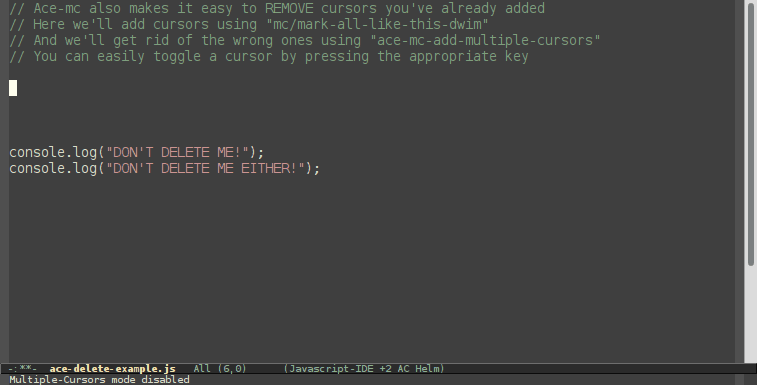
Org-mode is a great tool for organizing your todo lists, ideas, and notes. One of the pain points for me, though, is keeping all of my notes in the proper categories.
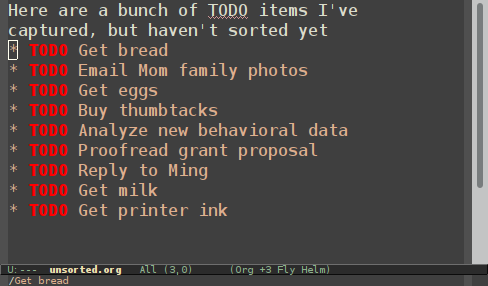
Ideally, I want these tasks to be sorted.
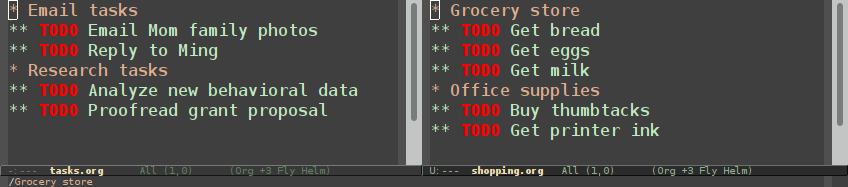
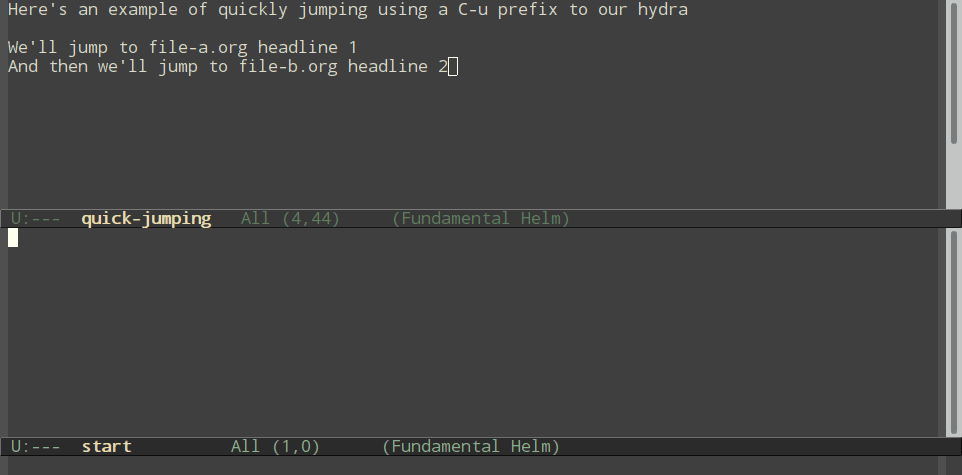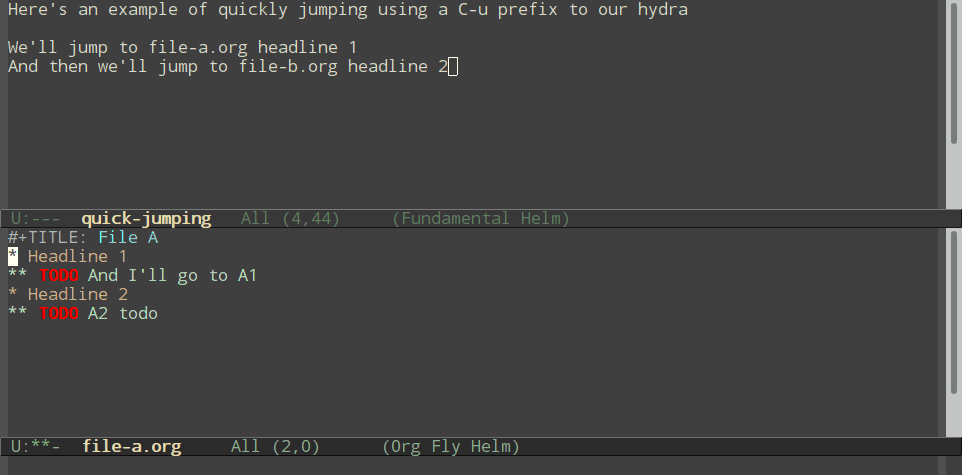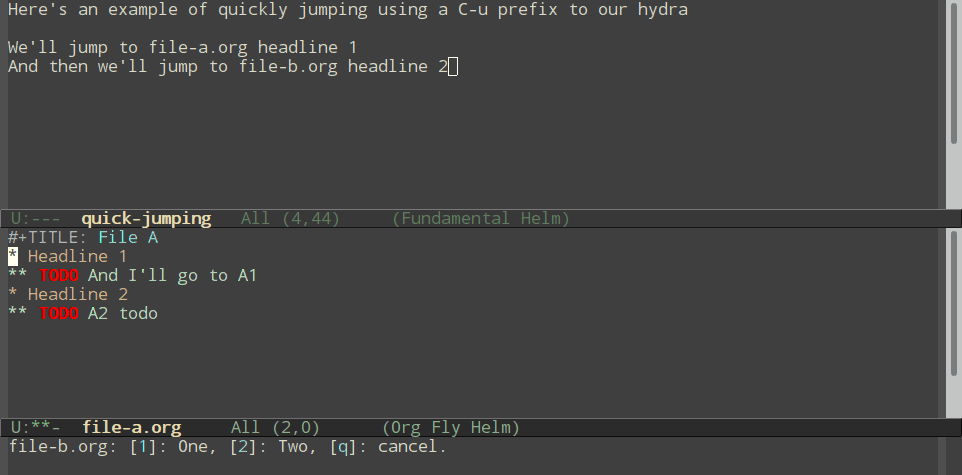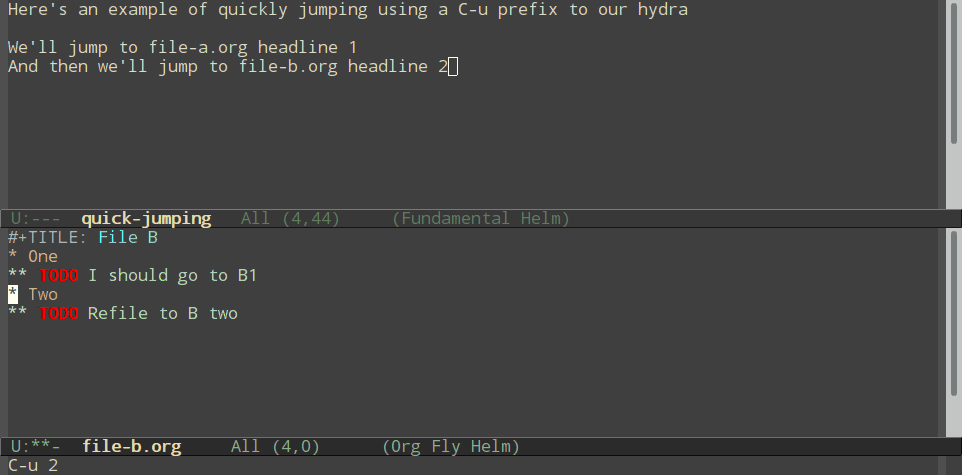
Normal refiling can be pretty slow. In this post, I'll show how to use the hydra package with simple macros and elisp functions to achieve fast refiling (and jumping) with just one or two keystrokes. The end result (code here) looks like this:
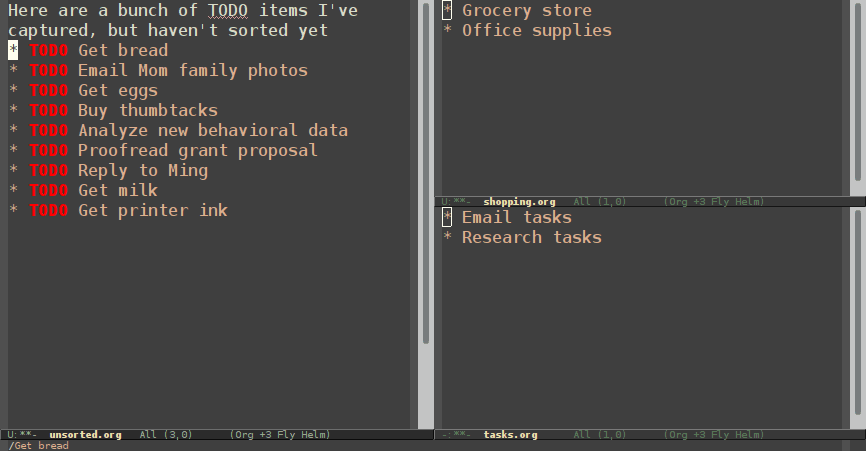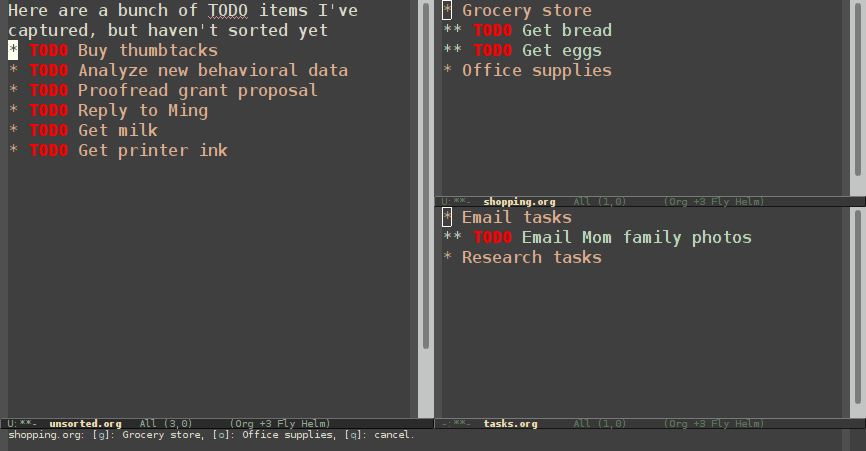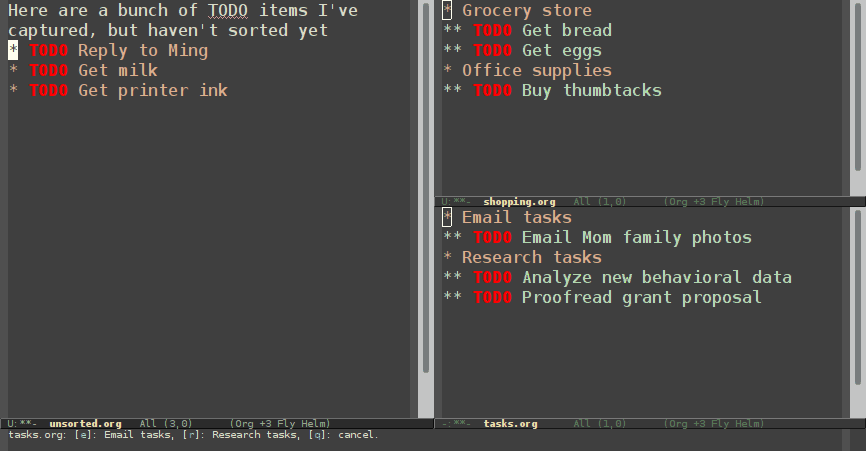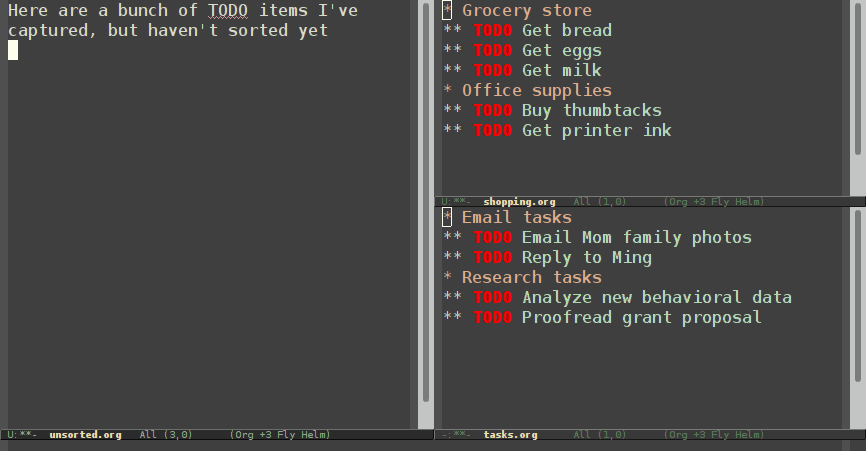
Why use hydras to refile?
Using hydras allow you to quickly repeat commands. Using nested hydras you can make most refile targets available in one or two keystrokes. When you're refiling a bunch of items, this goes from typing
C-c C-w Tasks RET |
Refile to tasks |
C-c C-w Boo RET |
Refile to "Books to read" which appears as a completion candidate |
C-c C-w RET |
Refile to last location |
to
f9 r |
My hydra keybinding |
t |
Refile to "Tasks" |
mb |
In my "maybe.org" file, refile to "Books to read" |
mb |
(Same as above) |
How to refile with hydra
Refiling to a specified location
If you look at the documentation for org-refile, you'll see there's
an optional argument RFLOC that allows you to programmatically
specify a refile location. It doesn't mention what format it should be
in, but a quick search brings up
a Stack Exchange answer that
shows the format and gives the following example of how to use it:
|
|
This is great! We can use this to bind keys to expressions like
(my/refile "someday-maybe.org" "Someday/Maybe"). One problem with
this is that we'd have to keep pressing the hotkeys over and over
again to refile a bunch of tasks in a row.
Using Hydra
So let's use a hydra to make refiling much faster.
|
|
For each keybinding, we provide:
- The key (e.g. "g")
- The command which refiles to a specific location
- A hint, which describes what the key does (e.g. "Refile to Grocery store")
I also use the :foreign-keys key to continue running the hydra, so I
can move to a headline using C-n and C-p without exiting the hydra
and having to call it again.
With just these commands, you can already begin to refile quickly.
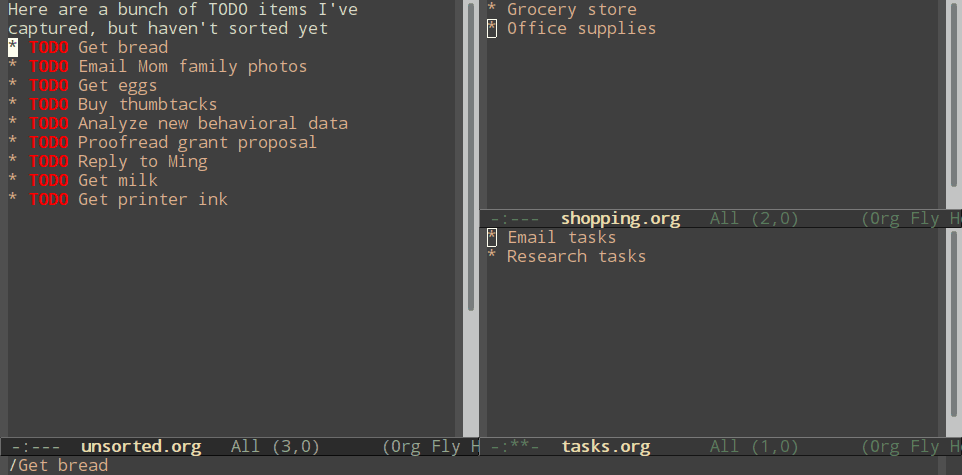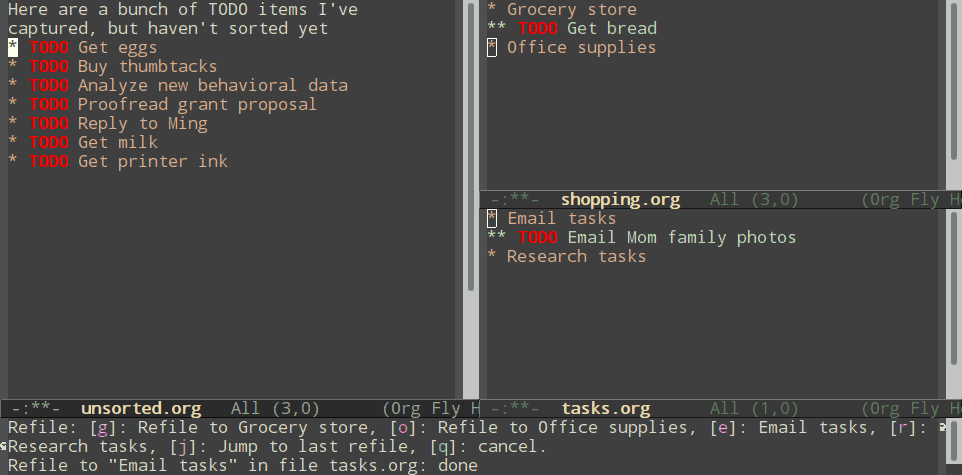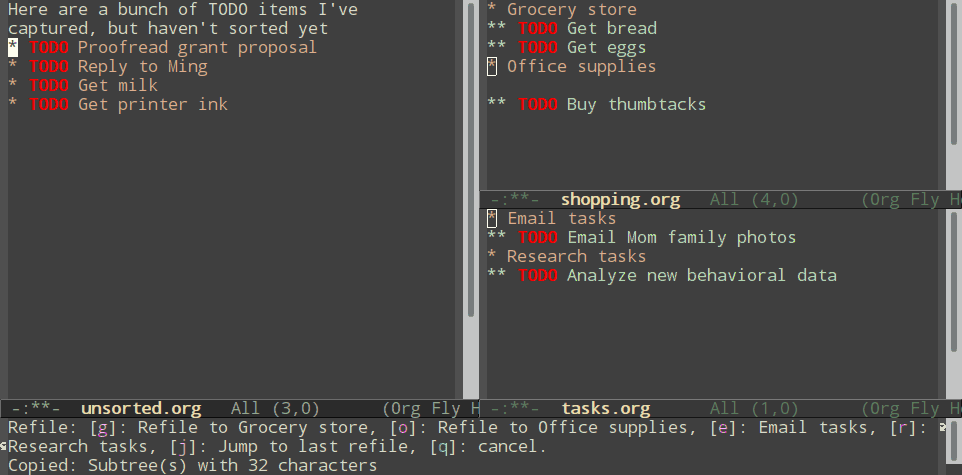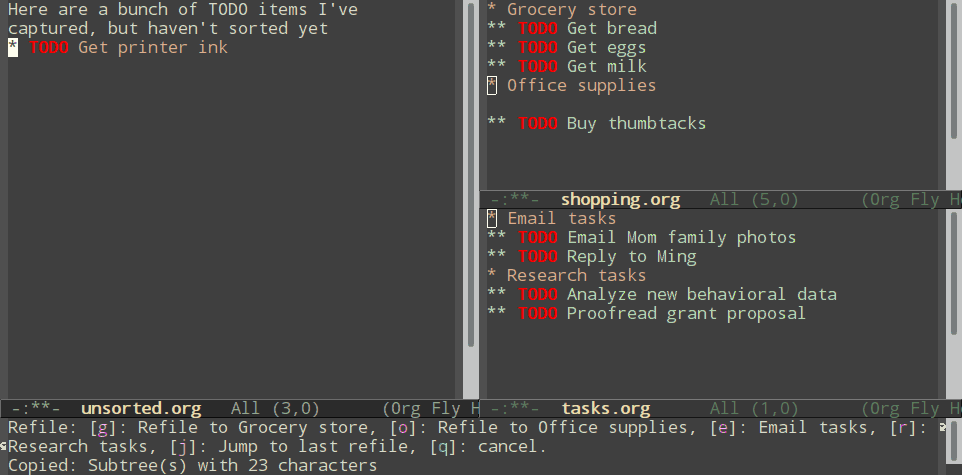
Nested hydras
But what happens when you have a lot of headlines to refile to? If you keep adding headlines, you might get a giant hydra like this:
|
|
You might find that you run out of keybindings fairly quickly. Here we had to start using uppercase letters because lowercase keys were overlapping.
By using nested hydras we can break refiling into two keystrokes: The first for the file and the second for the headline. This moves us from using 26 keys to $26^2 = 676$ possible locations to refile to (and if you use uppercase it's 2704!).
Here's how you can do a simple nested hydra, for refiling into three files (File A, B, and C), each with two headlines (roughly named "1" and "2").
|
|
I find the easiest way to construct a nested hydra is to use the
:after-exit keyword to pop back to the parent hydra.
We can see that refiling again is pretty straightforward.
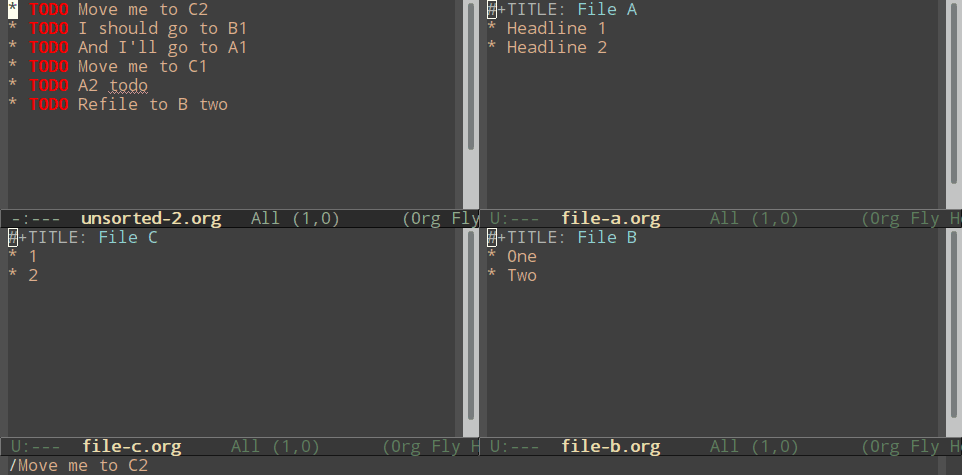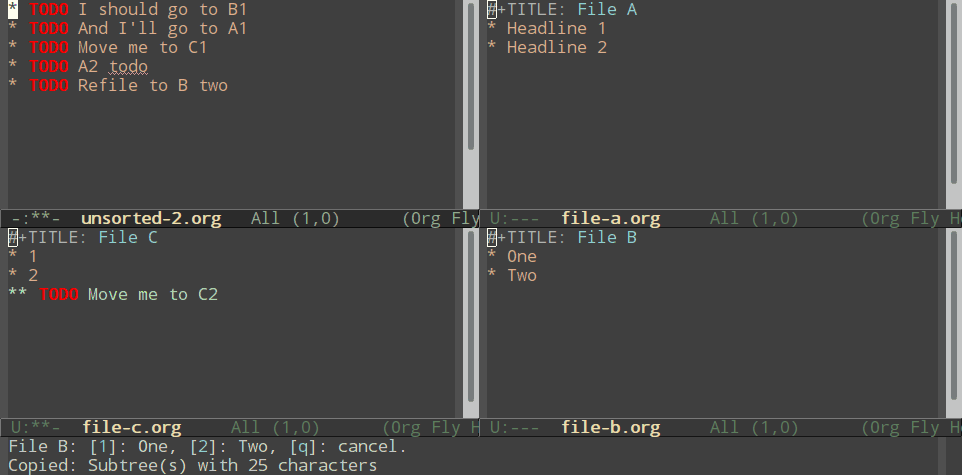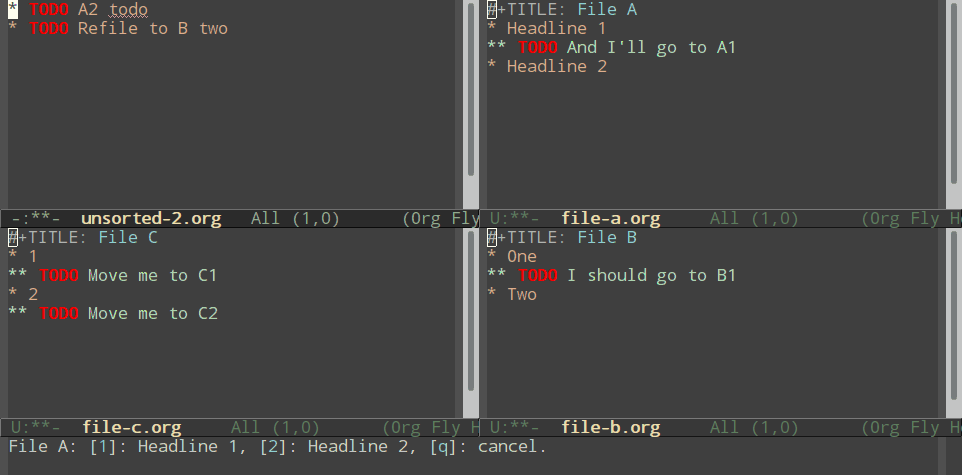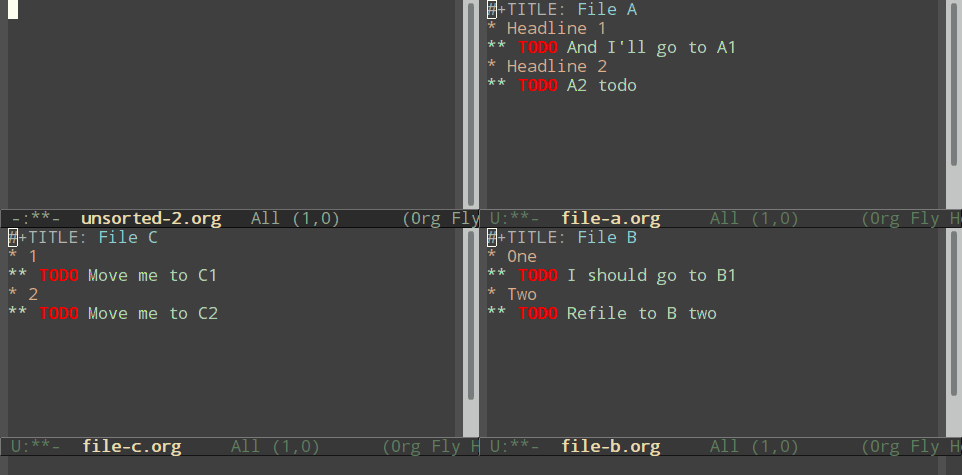
Using macros to make hydras
One problem with writing hydras this way is that it gets ugly pretty quickly, with a lot of redundant code. Notice how we repeatedly have to specify the file in each file's hydra, even though it doesn't change within it. Also note that the hydra hint is the same as the headline.
We can write an Elisp macro, to do the heavy lifting in creating our hydras, so we only have to specify a file once:
|
|
This makes defining our file hydras way simpler. Now our previous code simplifies to:
|
|
Great! Now our code is a bit cleaner, and adding new refile targets is
as easy as adding a ("Key" . "Headline") pair to a list.
Extra goodies
Using the previous code allows you to do most of your refiling tasks quickly and easily. I've made some modifications to the code to have the following features.
- Be able to jump (without refiling) to a headline by using a
C-uprefix- And quit the hydra if we jump, so we don't accidentally refile things on the next key press.
- Be able to refile while you're using
org-capture - Be able to refile in
org-agenda - Deal with some bugs:
- Don't refile when a headline doesn't exist
- Use
with-current-bufferso we don't accidentally switch to the buffer we're refiling to
All the code for this is available here, as a gist.
Note: Problems with current methods
Why did I use hydras to refile in the first place? There were a few
problems I was having with org-refile. Some of these can be solved
with some customizations that I wasn't aware of before.
Selecting refile targets can be slow
(length (org-map-entries 1 nil 'agenda))tells me I have 5208 entries in my agenda files at this time of writing. Even using a narrowing framework likehelm, it takes a long time to narrow down to the headline I want. And generally there are specific categories I do most of my refiling to. (Note: You could use the:tagsetting inorg-refile-targetsto limit refile targets to specific headlines. This might work well)You can limit the
:maxleveloforg-refile-targets, but unless I set it to "1" this doesn't speed things up much since most of my entries are level 1 or 2. Also, I like the ability to refile to any location when I need to.One option is to set
org-refile-cache, so you don't have to generate all refile targets every time you refile.You can also use
org-refile-target-verify-functionto limit locations you refile to, like "non-DONE tasks", "only projects", "headlines with children", etc. This can become slow as the function needs to be run on all possible candidates. (But in combination withorg-refile-cache, this can be less painful.)Refiling many headlines can be really slow
If you follow Bernt Hansen's org-mode guide, you might have a "refile.org" capture bucket of things to refile later. For me, sequential headlines aren't necessarily related and can be refiled to many places. Picking places, again, takes several keystrokes, which is kind of annoying.
Why not just use
org-captureto directly refile to headlines?Normally, when using
org-capture, I actually do capture directly to the headline I want. A problem with this, though, is that I need to have capture templates not just for each headline I want to capture to, but for each style/template I'd like to capture. I'd like to have different templates for things like "events", "events mentioned in emails" (so org-capture can automatically add the email link), "emails I need to reply to" and so forth.You can refile from
org-capture, but again this runs into my first problem.Why not batch refile with
org-agenda?I do this sometimes too. However, sometimes getting things I want to refile into the agenda in the first place is really cumbersome, and I'd like to navigate the tree structure of org mode (rather than flattening things with org-agenda).
I still use normal org-refile somewhat frequently, but refiling and
jumping using hydras saves me a fair amount of keystrokes