I work as a Unix Systems Administrator for UC Berkeley’s Rescomp and it occasionally comes up that sysadmins generally prefer vim while programmers prefer Emacs. The reasoning for this is that vim or vi is generally more available on servers and generally has a more consistent interface across servers. That is, if you use Emacs, you generally have a hefty .emacs file, and using an unconfigured Emacs is painful.
I think it’s no longer the case that Emacs isn’t installed by default. I’ve only ever had to use vim a handful of times, and the only thing I really needed to know was how to
- Insert text (
i)
- Save & Exit (
Esc : wq ENTER)
However, I’m a sysadmin that prefers Emacs, and there are a number of reasons why using Emacs is very helpful for sysadminning.
Dired
Dired mode is Emacs’s visual “directory editor”, and it makes navigating and operating on files much easier than just using the command line.
Using marks
One task that’s very easy in Dired that’s really cumbersome to do elsewhere is repeated grepping. Say, for example, that I want to find files with “hello” in them. In Dired I do this by pressing % g and entering the string.
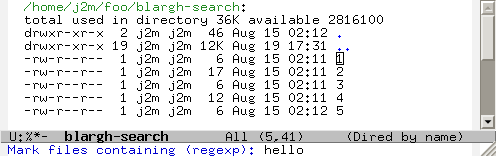
And what I get is a number of marked files (in orange), that I can easily, among other things:
- copy (
C)
- move/rename (
R) (even to another server with Tramp!)
- change the mode of (
M)
- run a shell command on (
!)
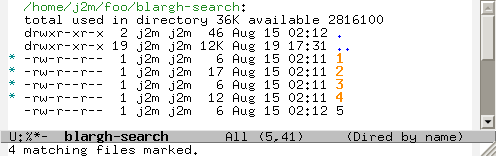
Now I can filter out files that don’t match by pressing t k (which toggles, then kills lines).
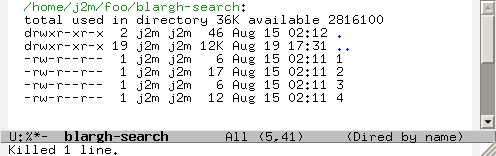
Now say I forgot that I also need the files to contain “world” somewhere in them. I just repeat the process by pressing % g again and entering “world” to get a list of marked files that contain both “hello” and “world”.
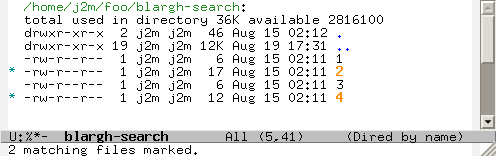
And now it’s really easy to do any operations on them.
In bash, however, it feels a little more clumsy for me. It’s possible to search by doing:
But if I remember later that it also has to contain “world”, I have to go edit the last command to be:
grep -lr hello . | xargs grep -l world
And now I just get a list of files. Say now that I want to copy these files somewhere. I have to again tack on another command, like so:
grep -lr hello . | xargs grep -l world | xargs -n1 -i cp {} /some/directory
It gets really cumbersome, and it requires you to remember how to use substitute arguments like {} in xargs. And you might also have to hope your file names don’t contain whitespace. With Dired, you really don’t have to worry about these kinds of things. Dired’s marking system makes a bunch of operations super convenient.
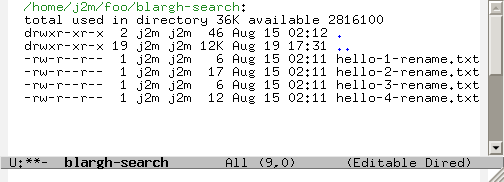
Edit Dired
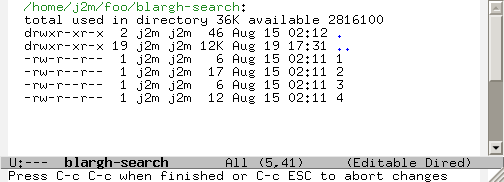
“Edit Dired” mode also just makes it so much easier to rename files in bulk. Instead of having to think of a regexp or sed expression to use for rename or whatever, I can just use C-x C-q, define a macro (or use query-replace) , and save the buffer. Dired automatically does all the renaming for you.
Make the Dired editable by pressing C-x C-q:
Create a macro to rename files (or use query-replace):
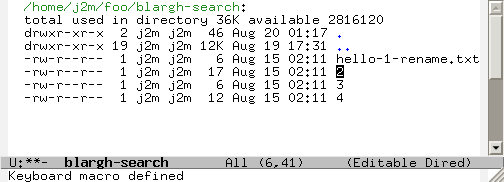
Apply to all files, then save the buffer:
Dired X
Dired X is also very useful. You load it by putting
in your .emacs
One of the cool things it can do is automatically guess the shell command you want to perform on a file. Say that I’ve forgotten the command to extract a .tar.gz file. Well, Dired X will remember for me!
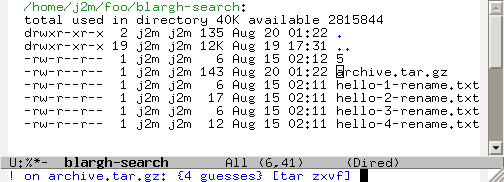
As you can see, it correctly suggests tar zxvf. Quite handy, huh?
Tramp
Tramp mode, combined with Dired, also just makes it really easy to move files around. I can browse directories on a remote server and say to myself “I’d like to have that locally” and copy it very quickly to my computer, without having to type scp and enter in the entire path. Another situation where this is useful is copying a file between two servers that have a firewall between each other. And this has actually happened for me on several occasions. Normally what I have to do is something like:
scp server1:/path/to/file .
scp file server2:/path/to/file
rm file
But with Tramp mode I can just copy it, quickly changing the server name in /ssh:server1:/path/to/file to /ssh:server2:/path/to/file
Tramp also makes it really easy to view images and PDFs on remote servers that don’t have X11, since Emacs can display images and PDFs.
It’s even possible to remotely edit files as root using /sudo:server:/path/to/file, although this doesn’t work out of the box. You’ll need to add this to your .emacs
(add-to-list 'tramp-default-proxies-alist
'((and (string-match system-name
(tramp-file-name-host (car target-alist)))
"THISSHOULDNEVERMATCH")
"\\`root\\'" "/ssh:%h:"))
This allows you to sudo into remote servers, but also prevents it from interfering with sudoing locally.
I can also use M-x ediff to compare two files on different servers, and selectively merge differences.
So these are just a few reasons why Emacs can come in handy for a sysadmin, or any normal user for that matter. Tramp in conjunction with Dired make it extremely easy to handle files on a number of servers.
 Josh Moller-Mara
Josh Moller-Mara